| Kaggle实战入门(二)之房价预测Housing Prices Competition | 您所在的位置:网站首页 › Java 官方文档 官方教程Java 官方文档 API中文手册Java › Kaggle实战入门(二)之房价预测Housing Prices Competition |
Kaggle实战入门(二)之房价预测Housing Prices Competition
|
这是博主第二个kaggle项目,Housing Prices Competition。这个项目是基于波士顿房价改编的数据集对房子的价格进行预测。虽然是基于波士顿房价数据集,但改编过后有着80多个数据特征,还是有一定难度的。下面给大家分享一下我的做法把,同样地在kaggle上排到了前10%的成绩。 先来初步观察一下我们这次要用到的数据集 import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt sns.set(font_scale=1) train=pd.read_csv('train.csv') test=pd.read_csv('test.csv') train.head()
使用train.corr()参数来查看我们每一个特征对于’SalePrice’之间的影响程度
将训练集和数据集的数据进行合并,开始我们的数据处理 trainrow=train.shape[0] testrow=test.shape[0] testids=test['Id'].copy() y_train=train['SalePrice'].copy() data=pd.concat((train,test)).reset_index(drop=True) data=data.drop('SalePrice',1) data=data.drop('Id',axis=1)(1).异常值的处理 在数据集当中有两个特征(GrLivArea,GarageYrBlt)是有离群值和异常值的,所以我们优先处理了这两个特征。 sns.scatterplot(x='GrLivArea',y='SalePrice',data=train)
(2).缺失值的处理 找出我们数据集中含有缺失值的特征 missing=data.isnull().sum().sort_values(ascending=False) missing=missing.drop(missing[missing==0].index) missing
使用data.info()可以查看特征的类型 data.info()①分类型特征填补 data['PoolQC']=data['PoolQC'].fillna('NA') data['MiscFeature']=data['MiscFeature'].fillna('NA') data['Alley']=data['Alley'].fillna('NA') data['Fence']=data['Fence'].fillna('NA') data['FireplaceQu']=data['FireplaceQu'].fillna('NA') data['GarageCond']=data['GarageCond'].fillna('NA') data['GarageQual']=data['GarageQual'].fillna('NA') data['GarageFinish']=data['GarageFinish'].fillna('NA') data['BsmtExposure']=data['BsmtExposure'].fillna('NA') data['BsmtCond']=data['BsmtCond'].fillna('NA') data['BsmtQual']=data['BsmtQual'].fillna('NA') data['BsmtFinType2']=data['BsmtFinType2'].fillna('NA') data['BsmtFinType1']=data['BsmtFinType1'].fillna('NA') data['Exterior2nd']=data['Exterior2nd'].fillna('NA') data['Exterior1st']=data['Exterior1st'].fillna('NA') data['MasVnrType']=data['MasVnrType'].fillna('NA') data['GarageYrBlt']=data['GarageYrBlt'].fillna(0) data['GarageType']=data['GarageType'].fillna(0) data['GarageArea']=data['GarageArea'].fillna(0) data['GarageCars']=data['GarageCars'].fillna(0) data['BsmtFinSF1']=data['BsmtFinSF1'].fillna(0) data['BsmtFinSF2']=data['BsmtFinSF2'].fillna(0) data['BsmtFullBath']=data['BsmtFullBath'].fillna(0) data['BsmtHalfBath']=data['BsmtHalfBath'].fillna(0) data['BsmtUnfSF']=data['BsmtUnfSF'].fillna(0) data['TotalBsmtSF']=data['TotalBsmtSF'].fillna(0) data['MasVnrArea']=data['MasVnrArea'].fillna(0)②连续型特征填补 data['LotFrontage']=data['LotFrontage'].fillna(data['LotFrontage'].dropna().mean()) data['MSZoning']=data['MSZoning'].fillna(data['MSZoning'].dropna().sort_values().index[0]) data['Utilities']=data['Utilities'].fillna(data['Utilities'].dropna().sort_values().index[0]) data['Functional']=data['Functional'].fillna(data['Functional'].dropna().sort_values().index[0]) data['SaleType']=data['SaleType'].fillna(data['SaleType'].dropna().sort_values().index[0]) data['Electrical']=data['Electrical'].fillna(data['Electrical'].dropna().sort_values().index[0]) data['KitchenQual']=data['KitchenQual'].fillna(data['KitchenQual'].dropna().sort_values().index[0])对missing进行检查,查看是否还有缺失值没有进行填补 missing=data.isnull().sum().sort_values(ascending=False) missing=missing.drop(missing[missing==0].index) missing
missing是一个空的列表,说明我们的缺失值已经全部填补完成了 (3).特征工程的建立 ①将一楼,二楼的面积加起来,用新特征总面积代替 data['Floorfeet']=data['1stFlrSF']+data['2ndFlrSF'] data=data.drop(['1stFlrSF','2ndFlrSF'],1)②将地面上和地下室的浴室数量加起来,用新特征总浴室数量代替 data['BathRooms']=data['BsmtFullBath']+data['BsmtHalfBath']*0.5+data['FullBath']+data['HalfBath']*0.5 data=data.drop(['BsmtFullBath','BsmtHalfBath','FullBath','HalfBath'],1)③将改建的年份替代为是否房子是否改建过,改建过的为1,否则为0 data['Removed']=0 data.loc[data['YearBuilt']!=data['YearRemodAdd'],'Removed']=1 data=data.drop('YearRemodAdd',1)(4).分类特征哑变量处理 使用pd.get_dummies()将所有的分类型特征转化成哑变量方便我们的模型进行学习 data=pd.get_dummies(data=data,columns=['MSSubClass'],prefix='MSSubClass') data=pd.get_dummies(data=data,columns=['MSZoning'],prefix='MSZoning') data=pd.get_dummies(data=data,columns=['OverallQual'],prefix='OverallQual') data=pd.get_dummies(data=data,columns=['OverallCond'],prefix='OverallCond')如果希望指定改变后的变量名称,可以添加prefix变量 data=pd.get_dummies(data=data,columns=['Street','Alley','LotShape','LandContour','Utilities','LotConfig','LandSlope','Neighborhood','Condition1','Condition2','BldgType','HouseStyle','BedroomAbvGr','KitchenAbvGr','TotRmsAbvGrd','Removed']) data=pd.get_dummies(data=data,columns=['RoofStyle','RoofMatl','Exterior1st','Exterior2nd','MasVnrType','ExterQual','ExterCond','Foundation','BsmtQual','BsmtCond','BsmtExposure','BsmtFinType1','BsmtFinType2','Heating','HeatingQC','CentralAir','Electrical','KitchenQual','Functional','FireplaceQu','GarageType','GarageFinish','GarageQual','GarageCond','PavedDrive','PoolQC','Fence','MiscFeature','SaleType','SaleCondition']) data.head()
(1).训练集和测试集的分离与数据标准化 from sklearn.preprocessing import StandardScaler x_train=data.iloc[:trainrow] x_test=data.iloc[trainrow:] scaler=StandardScaler() scaler=scaler.fit(x_train) x_train_scaled=scaler.transform(x_train) x_test_scaled=scaler.transform(x_test)使用StandardScaler对我们的数据进行标准化处理,可以提高模型的准确率 (2).数据建模 这次选用的模型是xgboost,也是我们机器学习竞赛上最为强大的模型。xgboost模型有自己独立的库和sklearn所带有的API。两种不同的调用对我们的模型准确率是有一定的影响的,一般情况下调用xgboost自己的库模型准确率会更高。 from xgboost import XGBRegressor reg =XGBRegressor(n_estimators=1000,eta=0.05).fit(x_train_scaled,y_train) print(reg.score(x_train_scaled,y_train)) pres = reg.predict(x_test_scaled) test['SalePrice']=pres col_n = ['Id','SalePrice'] a = pd.DataFrame(test,columns = col_n) a.to_csv('predit.csv',index=False) #调用sklearn所带有的API的做法,比较简单方便 import xgboost as xgb import pickle dtrain = xgb.DMatrix(x_train_scaled,y_train) param = {'silent':True ,'obj':'reg:linear' ,"subsample":1 ,"eta":0.05 } num_round = 1000 bst = xgb.train(param, dtrain, num_round) pickle.dump(bst, open("xgboostonhouse.dat","wb")) loaded_model = pickle.load(open("xgboostonhouse.dat", "rb")) dtest = xgb.DMatrix(x_test_scaled) pres = loaded_model.predict(dtest) test['SalePrice']=pres col_n = ['Id','SalePrice'] a = pd.DataFrame(test,columns = col_n) a.to_csv('predit.csv',index=False) #使用xgb自带库的调用方法,比较复杂 Part4.总结虽然是基于波士顿房价的数据集,但改编之后特征数量变得比较多,做起来更加需要我们耐心的分析每个特征应该做出怎样的处理。还是那句话,博主只是抛砖引玉,做法还有很多,如果有更好更高效的做法希望可以在评论区告诉博主,大家一起学习进步。 |

 可以看到我们这一次使用的数据集的特征数目是比较多的,有81个特征。 看到那么多的特征数,我们自然而然的会想到,81个特征里面是不是每一个都对我们的房价有着很重要的影响呢,所以接下来我们就来看一下每一个特征对房间的影响程度到底有多少。
可以看到我们这一次使用的数据集的特征数目是比较多的,有81个特征。 看到那么多的特征数,我们自然而然的会想到,81个特征里面是不是每一个都对我们的房价有着很重要的影响呢,所以接下来我们就来看一下每一个特征对房间的影响程度到底有多少。 画出热点图(颜色越深就说明这个特征对我们的房价影响越大)
画出热点图(颜色越深就说明这个特征对我们的房价影响越大) 提取出前十个重要的特征,再次画出他们的热点图
提取出前十个重要的特征,再次画出他们的热点图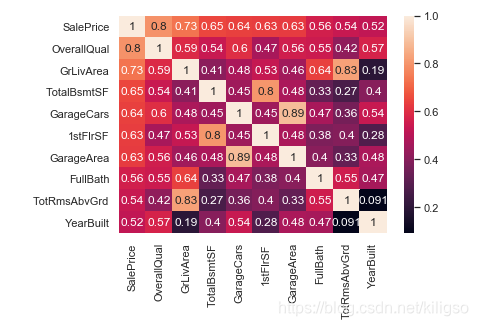 到这里,我们就可以清楚的看到对于房价影响最深的10个特征分别是:OverallQual(房屋的整体材料饰物的评分),GrLivArea(房子的面积),TotalBsmtSF(地下室总面积),GarageCars(车库的容量),1stFlrSF(1楼的面积),GarageArea(车库的面积),FullBath(地面上浴室的数量),TotRmsAbvGrd(地上不包括浴室的房间数),YearBuilt(房子建造的年龄)。 我们可以画出这十个特征与房价之间的依赖图,看下他们到底是怎样影响我们的房价的。
到这里,我们就可以清楚的看到对于房价影响最深的10个特征分别是:OverallQual(房屋的整体材料饰物的评分),GrLivArea(房子的面积),TotalBsmtSF(地下室总面积),GarageCars(车库的容量),1stFlrSF(1楼的面积),GarageArea(车库的面积),FullBath(地面上浴室的数量),TotRmsAbvGrd(地上不包括浴室的房间数),YearBuilt(房子建造的年龄)。 我们可以画出这十个特征与房价之间的依赖图,看下他们到底是怎样影响我们的房价的。 从我们的依赖图中可以看到有几个特征对于房价的影响是线性相关的(GrLivArea,TotalBsmtSF,1stFlrSF,GarageArea),房价会随着这几个特征的上升而上升,这就是我们81个特征当中的关键特征。kaggle社区上有参赛者会直接选择使用这十个特征来进行建模,这是可行的做法,但获得的分数并不会太高。
从我们的依赖图中可以看到有几个特征对于房价的影响是线性相关的(GrLivArea,TotalBsmtSF,1stFlrSF,GarageArea),房价会随着这几个特征的上升而上升,这就是我们81个特征当中的关键特征。kaggle社区上有参赛者会直接选择使用这十个特征来进行建模,这是可行的做法,但获得的分数并不会太高。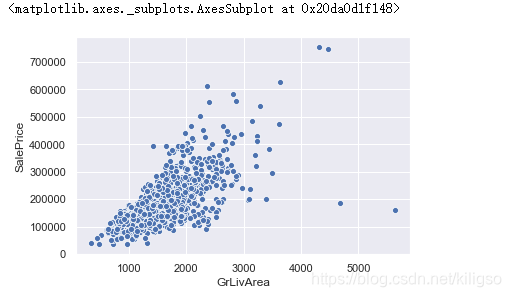 从散点图可以看到房价是随着居住面积的增加而上涨的,这符合我们的常识。但是右下角出现了两个离群值,面积增加了但是房价并没有增加。这是我们所不希望看到的情况,所以我们要将这两个离群值去掉。
从散点图可以看到房价是随着居住面积的增加而上涨的,这符合我们的常识。但是右下角出现了两个离群值,面积增加了但是房价并没有增加。这是我们所不希望看到的情况,所以我们要将这两个离群值去掉。 可以看到我们的GarageYrBlt特征当中出现了一个异常值2207,这表示车库是在2207年建立的,出现了一个穿越时空的车库。这明显就是一个异常值,所以我们要将它去掉。
可以看到我们的GarageYrBlt特征当中出现了一个异常值2207,这表示车库是在2207年建立的,出现了一个穿越时空的车库。这明显就是一个异常值,所以我们要将它去掉。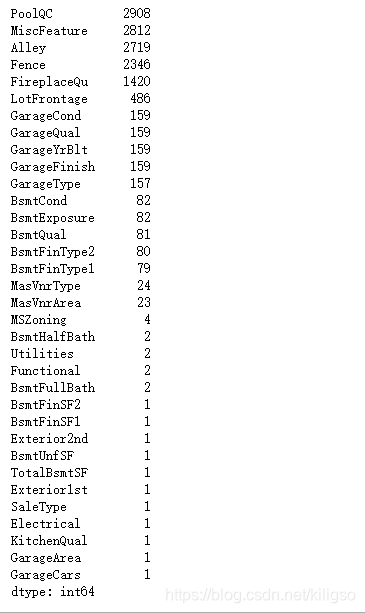 一共有34个特征有缺失值,说明我们接下来的是一个枯燥的填补缺失值的过程,为了方便,统一对分类型特征的缺失值填补‘NA’,对连续型特征的缺失值进行平均值或缺失值的填补。
一共有34个特征有缺失值,说明我们接下来的是一个枯燥的填补缺失值的过程,为了方便,统一对分类型特征的缺失值填补‘NA’,对连续型特征的缺失值进行平均值或缺失值的填补。
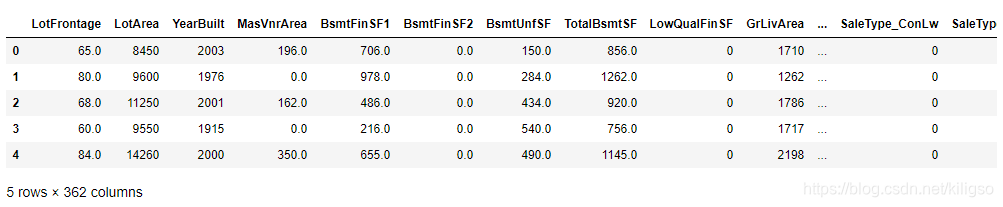 到这里我们的数据就处理完成了,处理过后的数据一共有362列,这当中绝大部分都是哑变量数据。
到这里我们的数据就处理完成了,处理过后的数据一共有362列,这当中绝大部分都是哑变量数据。【本文地址】